1. Why do we need a staggered DiD package for big data?
Recently, I noticed a pattern at seminars and conferences: presenters would acknowledge that they should use a staggered DiD estimator, but would say that doing so is infeasible in their context due to large sample size. To check, I wrote a simple panel data simulator with staggered treatment roll-out and heterogeneous treatment effects, simulated large samples, and applied these popular R packages for staggered DiD estimation:
-
didimputationfor implementing the approach of Borusyak, Jaravel, and Spiess (2022); -
didfor implementing the approach of Callaway & Sant’Anna (2021); and -
DIDmultiplegtfor implementing the approach of de Chaisemartin & D’Haultfoeuille (2020).
I found that only did could successfully estimate
staggered DiD with 100,000 unique individuals, and it took a while.
While many DiD applications consider only a small number of unique
individuals (e.g. state-level analysis with 50 states), DiD designs at
the household-level or firm-level using administrative data often
involve millions of unique individuals.
2. This package
I wrote DiDforBigData to address 4 issues that arise in
the context of large administrative datasets:
-
Speed: In less than 1 minute,
DiDforBigDatawill provide estimation and inference for staggered DiD with millions of observations on a personal laptop. It is orders of magnitude faster than other available software if the sample size is large. -
Memory: Administrative data is often stored on
crowded servers with limited memory available for researchers to use.
DiDforBigDatahelps by using much less memory than other software. -
Dependencies: Administrative servers often do not
have outside internet access, making it difficult to install
dependencies. This package has only two dependencies,
data.tablefor big data management andsandwichfor robust standard error estimation, which are already installed with most R distributions. Optionally, it will use thefixestpackage to speed up the estimation if it is installed. If theprogresspackage is installed, it will also provide a progress bar so you know how much longer the estimation will take. -
Parallelization: Administrative servers often have
a large number of available processors, but each processor may be slow,
so it is important to parallelize.
DiDforBigDatamakes parallelization easy as long as theparallelpackage is installed.
3. Demonstration
This section will compare didimputation,
did (using the default option as well as the
bstrap=F option), DIDmultiplegt (with option
brep=40), and DiDforBigData in R. I draw the
simulated data 3 times per sample size, and apply each estimator.
Results are presented for the median across those 3 draws. Sample Size
refers to the number of unique individuals. Since there are 10 simulated
years of data, and the sample is balanced across years, the number of
observations is 10 times the number of unique individuals. Replication
code is available here.
3.1 Point estimates
I verify that all of the estimators provide similar point estimates and standard errors. Here, I show the point estimates and 95% confidence intervals (using +/- 1.96*SE) for the DiD estimate at event time +1 (averaging across cohorts). The true ATT is 4 at event time +1. I also verify that two-way fixed-effects OLS estimation would find an effect of about 5.5 at event time +1 when the sample is large.
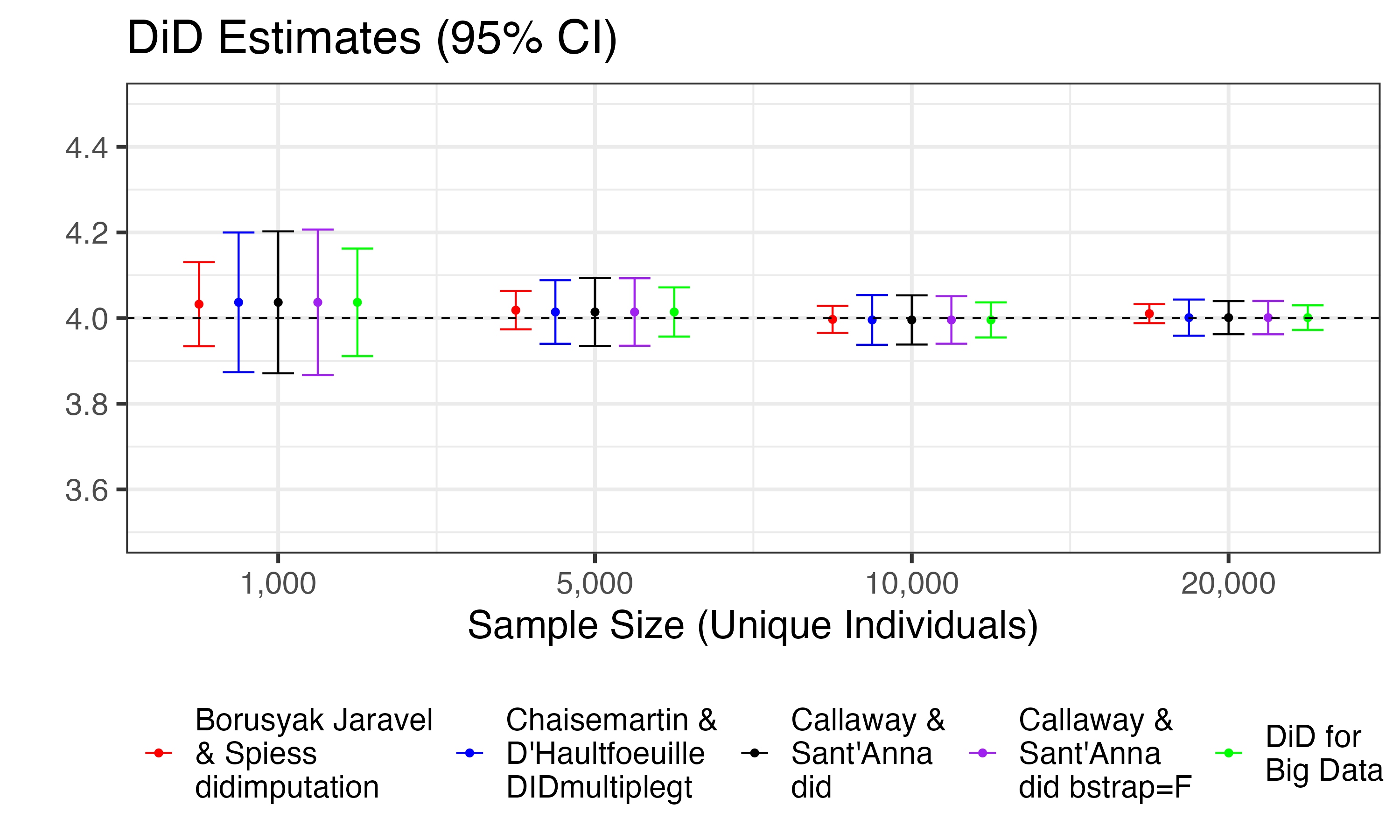
A caveat: did provides standard errors that correspond
to multiple-hypothesis testing and will thus tend to be wider
than the single-hypothesis standard errors provided by
didimputation and DiDforBigData.
3.2 Speed test
Small Samples: Here is the run-time required to complete the DiD estimation using each package:
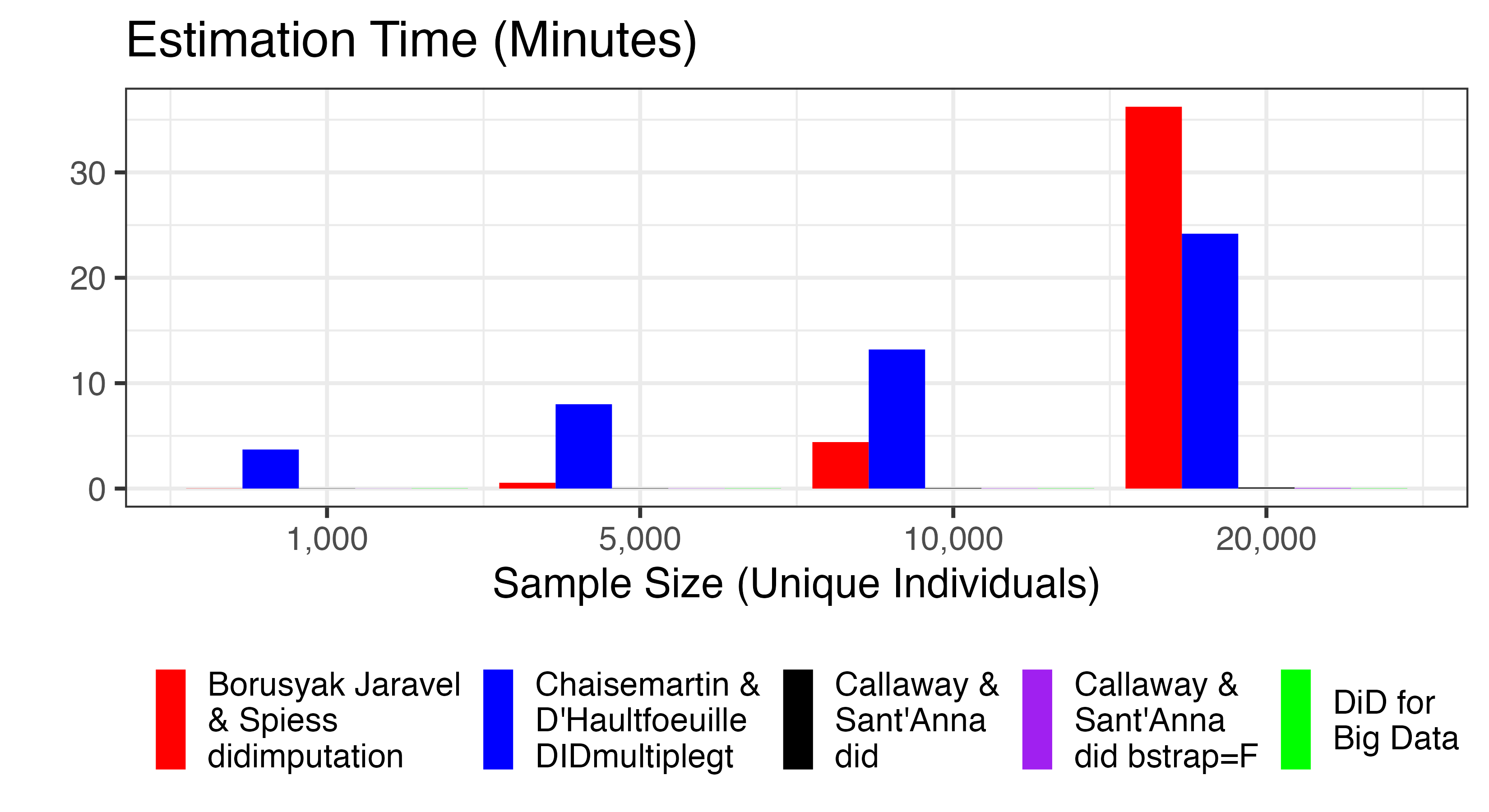
We see that, with 20,000 unique individuals, didimpute
and DIDmultiplegt have become very slow. I could not get
either approach to run successfully with 100,000 unique individuals, as
they both crash R. By contrast, did and
DiDforBigData are so fast that they can barely be seen in
the plot.
Large samples: Given the failure of
didimpute and DIDmultiplegt with 100,000
observations, we now restrict attention to did and
DiDforBigData. We consider much larger samples:
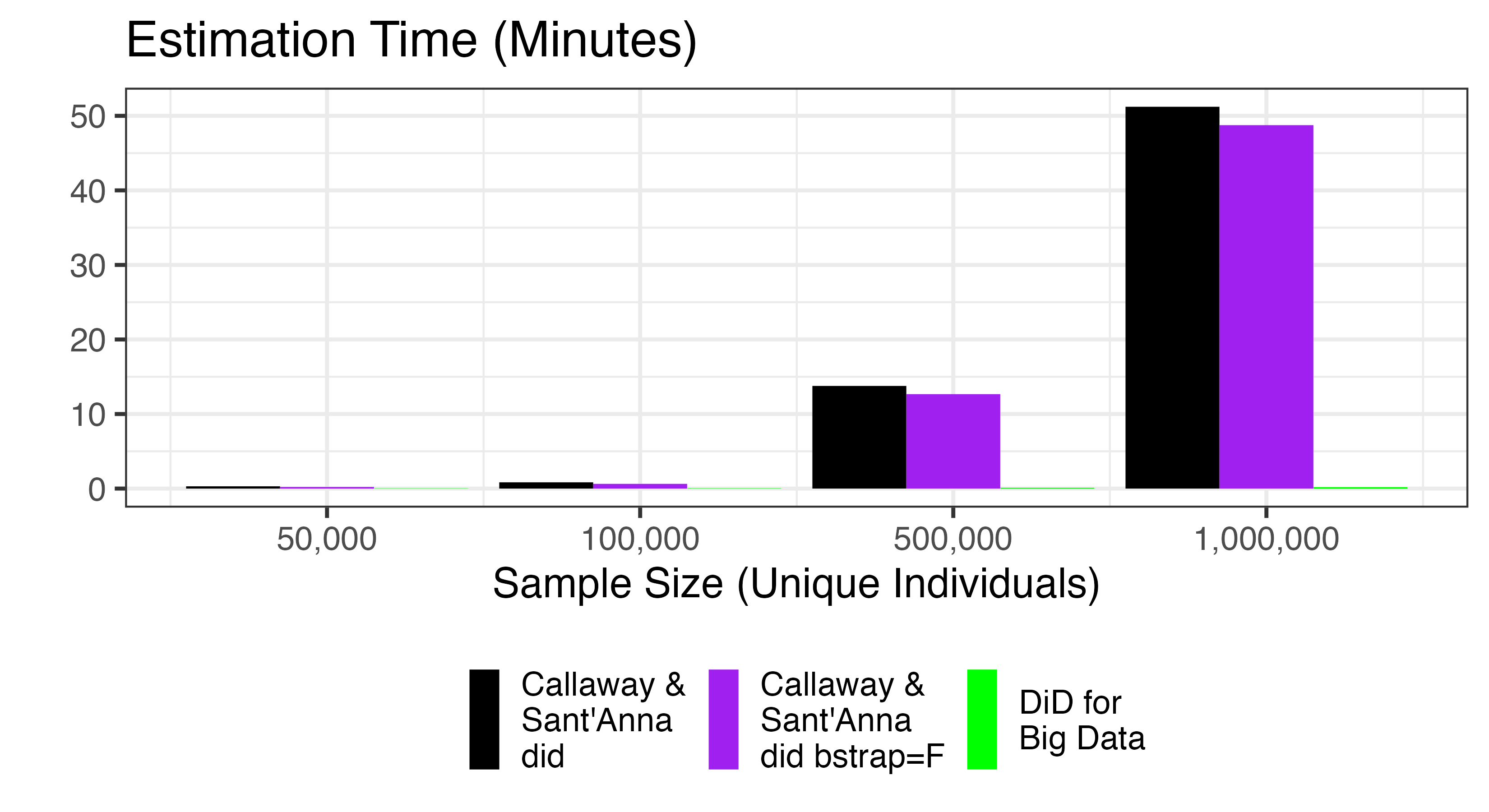
Even with 1 million unique individuals (and 10 million observations),
it is difficult to see DiDforBigData in the plot, as
estimation requires about half of a minute, versus nearly 1 hour for
did. Thus, DiDforBigData is roughly two
orders of magnitude faster than did when working with
a sample of one million individuals.
3.3 Memory test
Small Samples: Here is the memory used to complete the DiD estimation by each package:
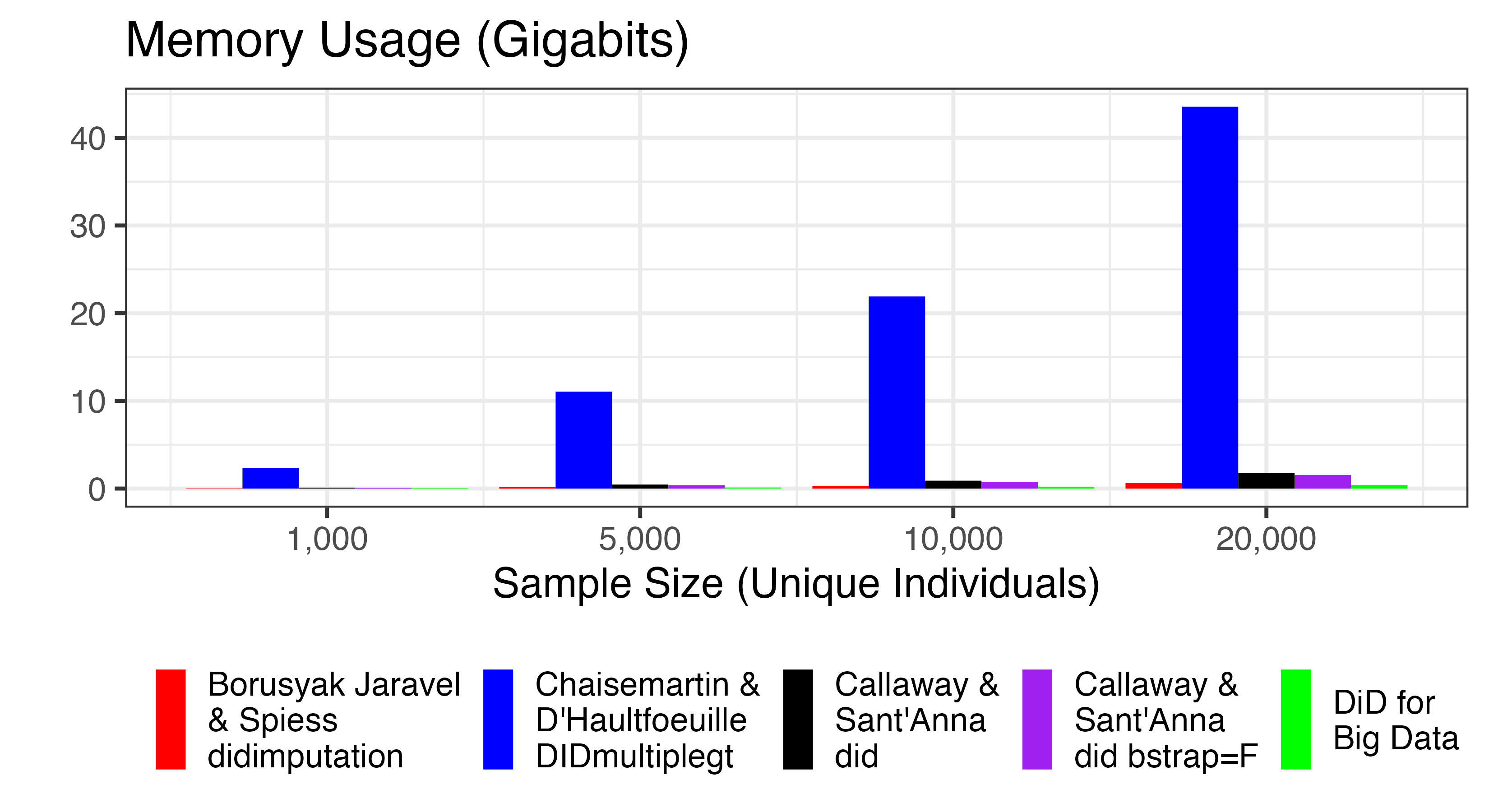
We see that DIDmultiplegt uses much more memory than the
other approaches. The other approaches all use relatively little memory
at these sample sizes.
Large Samples:
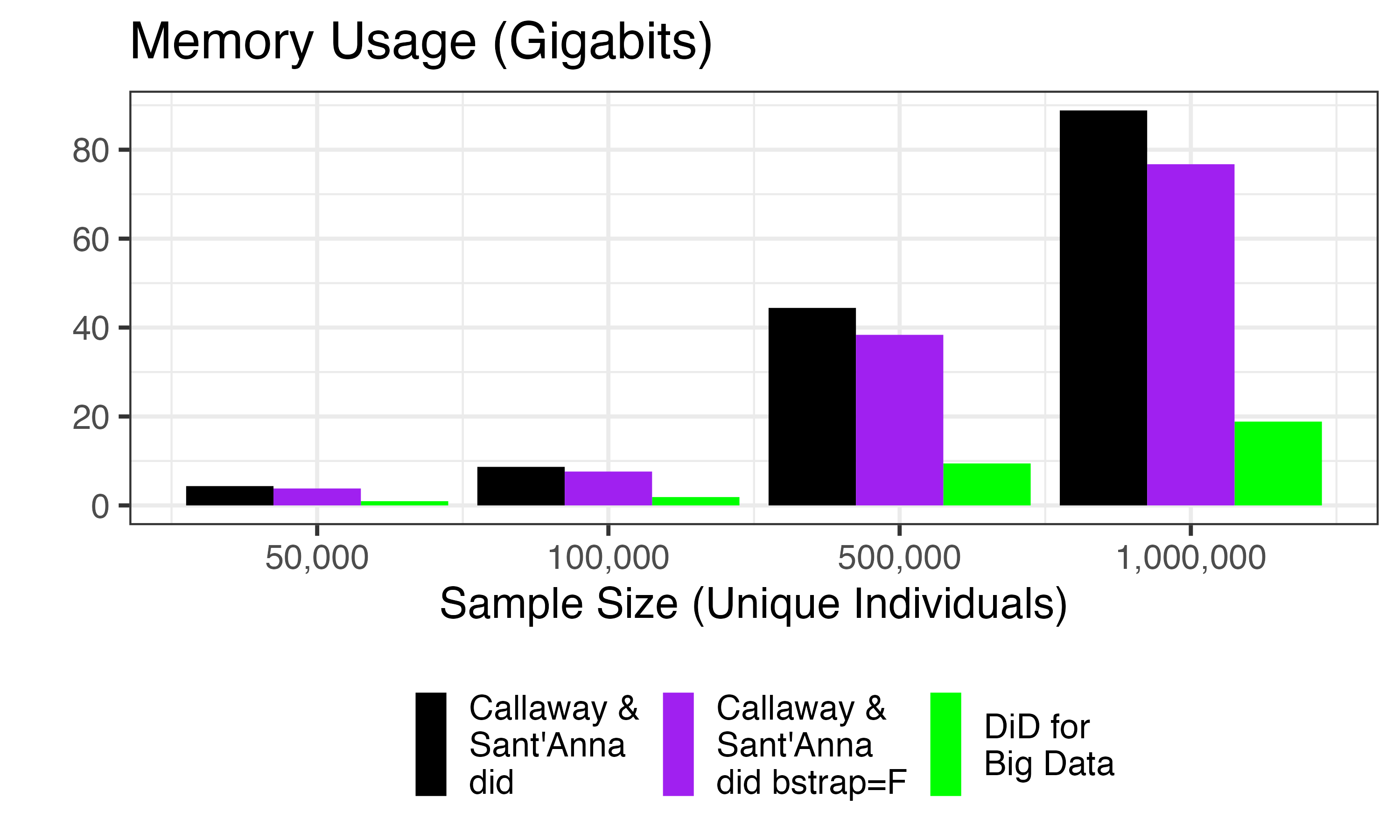
When considering large samples, we see that
DiDforBigData uses less than a quarter of the memory used
by did.